Virtio Network Device Failover
Support for Virtio Network Device Failover which has been merged for linux 4.17 presents an interesting study in interface design: both for operating systems and hypervisors. Read on for an article examining the problem domain, solution space and describing the current status of the implementation.
PT versus PV NIC
Imagine a Virtual Machine running on a hypervisor on a host computer. The hypervisor has access to a network to which the host is attached, but ow should guest gain this access? The answer could depend on the type of the netwok and on the network interface on the host. For the sake of this article we focus on Ethernet networks and NICs. In this setup a popular solution extends (bridges) the Ethernet network into the guest by exposing a virtual Ethernet device as part of the VM.
In most setups a single host NIC would be shared between VMs. Two popular configurations are shows below:

In the first diagram (on the left) the NIC exposes Virtual Function (VFs) interfaces which the hypervisor “passes through” - makes accessible to the guests. Using such Passthrough (PT) interfaces packets can pass between the guest and the NIC directly. For PCI devices, device memory can actually be mapped into the address space of the virtual machine in such as way that guest can actually access the device without invoking the hypervisor. In the setup on the right packets are passed between the guest and the NIC by the hypervisor. The hypervisor interface used by guest for this purpose would commonly be a PV - Para-virtual (i.e. designed for the hypervisor) NIC. One example would be the Virtio network device, used for example with the KVM hypervisor. By comparison, Microsoft HyperV guests use the netvsc device with its PV NICs.
Since the underlying packets are still handled by the physical NIC in both cases, it would be unusual for the second (PV) setup to outperform the first (PT) one. Besides removing some of the hypervisor overhead, passthrough allows driver within the guest to be precisely tuned to the physical device.
However the PV NIC setup obviously offers more flexibility - for example, the hypervisor can implement an arbitrary filtering policy for the networking packets. By comparison, with PT NICs we are limited to the features presented by hardware NICs which are often more limited: some of them only have simplest filtering capabilities. As an example of a simple and effective filtering/security measure, guest would often be prevented from modifying the MAC address of its devices, limiting guest’s access to the host’s network.
But even besides limitations of specific hardware the standardized interface independent of the physical NIC makes the system easier to manage: use of a standard driver within guest as well as a well known state of the device enable features such as live migration of guests between hypervisors: guests can often be moved with negligible network downtime.
Same can not be generally said with the passthrough setup, for example, one of the issues encountered with it is that even a small difference between hypervisor hosts in their physical hardware would require expensive reconfiguration when switching hypervisors.
Can not something be done with respect to performance to get the speed benefits of pass-through without giving up on live migration and similar advantages of standardized PV NIC setups? One approach could be designing a pass-through NIC around a standard paravirtualized interface. This is the approach taken by the Virtio Data Path Accelerator devices. In absence of such an accelerator, Virtual Network Device Failover presents another possible approach.
Network device Failover basics
Conceptually, the idea behind Virtual Network Device Failover is simple: assume that a standard PV interface only brings benefits part of the time. The system would change its configuration accordingly - e.g. when migration is required use the PV interface, when it’s not - use a PT device.
When possible hypervisor will pass through the NIC to the guest as a “primary” device. To reduce downtime, a “standby” PV device could be kept around at all times. When PV features are not required, hypervisor can add guest access to the primary PT device. At other times the standby PV interface is used.
Accordingly, guest would be required to switch over between primary and standby interfaces depending on availability of the primary interface.

An astute reader might notice that the above switching sounds a bit like the active-backup configuration of the bond and team network drivers in Linux. That is true - in fact in the past one of these drivers has often been used to implement network device failover. Let’s take a quick look at how active-backup can be used for network device failover.
Network Device Failover using active-backup
This text will use the term bond when meaning the network device created by either a bond or the team driver: the differences between these two mostly have to do with how devices are created, configured and destroyed and will not be covered here.
A bond device is a master software network device which can enslave multiple interfaces. In our case these would be the standby and the primary devices. For this, the bond master needs to be created and initialized with slave interface names before slaves are brought up. When priority of the primary interface is set higher than priority of the standby, the bond will switch between interfaces as required for failover.
The active-backup was designed to help create redundancy and improve uptime for systems with multiple NIC devices. To make it work for the virtual machine, we need guest to detect interface failure on the primary interface and switch to the stanby one. This can be achieved for example by removing the interface by making the hypervisor emulate hotplug removal request.
However the above might already hint at some of the issues with this approach to failover: first, bond needs to be set up by userspace. Configuring a bond for all devices unconditionally would be an option but would add overhead to all users. On the other hand, adding a slave to the bond would require bringing the slave down. For this reason to avoid downtime bond has to be created upfront, even if only the standby device is present during guest initialization.
Further, setting up an active-backup bond is considered a question of policy and thus is left up to guest admin. By comparison network failover is a mechanism - there’s no good reason not to use a PT interface if it is available to the guest. Should hypervisor want to force guest to create a bond, hypervisor would need a measure of control over guest network configuration which might conflict with the way some guest admins like to set up their networking.
Another issue is with device selection. Bond tends to address devices using their names. While recently device names under many Linux distributions became more predictable, it is not the case for all distributions, and specific naming schemes might differ. It is thus a challenge for the hypervisor to specify to the guest which interfaces need to be bonded together.
To help reduce downtime, the bond will also broadcast location information on a network on every switch. This is not too problematic but might cause extra load on the network - likely unnecessary in case of virtual device failover since packets are in the end traveling over the same physical wire.
Maintaining a consistent MAC address for the guest is necessary to avoid need for all guest neighbours to rediscover the MAC address using the slow APR/Neighbour Discovery. To help with that, bond will try to program the MAC address into the primary device when it’s attached. If MAC programming is disabled as a security measure (as described above) bond will generally fail to attach to this slave.
Failover goals; 1,2 and 3 device models
The goal of the network device failover support in Linux is to address the above problems. Specifically: - PT cards with MAC programming disabled need to be supported - configuration should happen automatically, with no need for userspace to make a policy decision - in particular the primary/standby pair of devices should be selected with no need for special configuration to be passed from hypervisor - support as wide a range of existing network setup tools as possible with minimal changes
Most of the design seems to fall out from the above goals in a manner that is more or less straight-forward: - design supports two devices: a standby PV device is present at all times and used by default; a primary PT device is used by preference when it’s available - failover support is initialized by the PV device driver, e.g. in the case of Virtio this happens when the Virtio-net driver detects a special feature bit set by the hypervisor on the Virtio PV device - to support devices without MAC programming, both standby and primary can be simply required to be initialized (e.g. by the hypervisor) with the same MAC address - in that case, MAC address can also used by failover to locate and enslave the primary device
However, the requirement to minimize userspace changes caused a certain amount of debate about the best way to model the failover setup, with the debate centered around the number of network device structures being created and exposed to userspace. It seems worthwhile to list the options that have been debated, below:
1-device model
In a 1-device model userspace sees a single failover device at all times. At any time this device would be either the PT or the PV device. As userspace might need to configure devices differently depending on the specific driver used, a new interface would have to be introduced for kernel to report driver changes to userspace, and for userspace to detect the actual driver used. However, as long as userspace does not contain any driver-specific code, userspace tools that already work with the Virtio device seem to be guaranteed to keep working without any changes, but with a better performance.
To best of author’s knowledge, no actual code supporting this mode has ever been posted.
2-device model
In a 2-device model, the standby and primary devices are exposed to userspace as two network devices. The devices aren’t independent: primary device is a slave and standby is the master in that when primary is present, standby device forwards outgoing packets for transmission on the primary device.
PT driver discovery and device specific configuration can happen on the slave interface using standard device discovery interfaces.
Both portable configuration affecting both PV and PT devices (such as interface MTU) and the configuration that is specific to the PV device will happen on the master interface.
The 2-device model is used by the netvsc driver in Linux. It has been used in production for a number of years with no significant issues reported. However, it diverges from the model used by the bond driver, and the combination of PV-specific and portable configuration on the master device was seen by some developers as confusing.
3-device model
The 3-device model basically follows bond: a master failover device forwards packets to either the primary or the standby slaves, depending on the primary’s availability.
Failover device maintains portable configuration, primary and standby can each have its own driver-specific configuration.
This model is used by the net_failover driver which has been present in Linux since version 4.17. This model isn’t transparent to userspace: for example, presence of at least two devices (failover master and primary slave) at all times seems to confuse some userspace tools such as dracut, udev, initramfs-tools, cloud-init. Most of these tools have since been updated to check the slave flag of each interface and ignore interfaces where it is set.
3-device model with hidden slaves
It is possible that the compatibility of the 3-device model with existing userspace can be improved by somehow hiding the slave devices from most legacy userspace tools, unless they explicitly ask for them.
For example it could be possible to somehow move them to some kind of special network namespace. No patches to implement this idea have been posted so far.
Hypervisor failover support
At the time of this article writing, support for virtual network device failover in the QEMU/KVM hypervisor is still being worked upon. This work uncovered a surprising number of subtle issues some of which will be covered below.
Primary device availability
Network Failover driver relies on hotplug events for the primary device availability. In other words, to make the primary device available to the guest the hypervisor emulates a hot-add hotplug event on a bus within VM (e.g. the virtual PCI bus). To make the primary device unavailable, a hot-unplug event is emulated.
Note that at the moment most PCI drivers expect a chance to be notified and execute cleanup before a device is removed. From hypervisor’s point of view, this would mean that it can not remove the PT device and e.g. can not initiate migration until it receives a response from the VM guest. Making hypervisor depend on guest being responsive in this way is problematic e.g. from the security point of view.
As described earlier in a lwn.net article most drivers do not at the moment support surprise removal well. When that is addressed, hypervisors will be able to switch to emulate surprise removal to remove dependency on guest responsiveness.
Existing Guest compatibility
One of the issues that hypervisors take pains to handle well is compatibility with existing guests, that is guests which have not been modified with virtual network device failover support.
One possible issue is that existing guests can become confused if they detect two Ethernet devices with the same MAC address.
To help address this issue, the hypervisor can defer making the primary device visible to the guest until after the PV driver has been initialized. The PV driver can signal to the hypervisor guest support for the virtual network device failover.
For example, in case of the virtio-net driver, hypervisor can signal the support for failover to guest by setting the VIRTIO_NET_F_STANDBY host feature bit on the Virtio device. If failover is enabled, the driver can signal failover support to hypervisor by setting the matching VIRTIO_NET_F_STANDBY guest feature bit on the device.
After detecting a modern guest with failover support, the hypervisor can hot-add the primary device. Device will have to be hot-removed again on guest reset - in case the VM will reboot into a legacy guest without failover support.
This is also helpful to avoid initializing a useless failover device on hypervisors without actual failover support.
As of the time of writing of this article, the definition of the VIRTIO_NET_F_STANDBY and its support are present in Linux. Some preliminary hypervisor patches with known issues have been posted.
Packet filtering issues
Early implementations of the failover in QEMU were originally tested with an emulated NIC. When tested on a physical one, it was quickly detected that for many configurations significant downtime occurs.
The reason has to do with how incoming packets are processed by the host NIC. Generally, a packet is matched against some rules (e.g. the destination MAC is matched using a forwarding filter) and a decision is made to forward the packet either to the hypervisor or to a guest through a VF.

Consider again a hypervisor transitioning between configurations where a primary passthrough VF is available to a configuration where it is unavailable to the guest.
When the primary device is available to the guest we want incoming packets with destination MAC matching the device to be forwarded through the primary. In many configurations this happens immediately when the hypervisor programs the MAC into the VF. In these setups, when primary device becomes unavailable to guest, unless special steps are taken, incoming packets will still be filtered to it and eventually dropped.
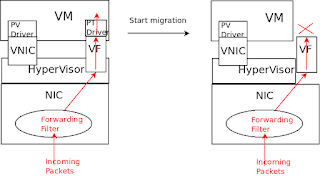
One possible fix is have the hypervisor update the host NIC filtering, e.g., by updating the MAC of the VF to a different value. Another is to change the filtering on the host NIC such that it only happens when a driver is attached to the VF. This seems to already be the case for some drivers (such as ice,mlx) and so one can argue that others should be changed to behave consistently. Another approach would be to teach hypervisor to detect the difference and handle both types of behaviour.
Conversely, when the primary interface becomes available to guest, we would like packets to start flowing through the primary but only after the driver is bound to it. Again, on some devices hypervisor might need to intervene to update the forwarding filter on the host NIC. One issue is that it might take guests a while to detect a hot-add event and bind a driver to the primary device. This is because hotplug is not generally considered a data path operation. Should the host NIC filter be updated by the hypervisor immediately on hot-add, there will be a large window during which guest driver has not been initialized yet.

As a possible fix, hypervisors can detect that the pass-through driver has been attached to device. For example, drivers enable bus-mastering on the device when they start using it, and disable it when they stop using it. Hypervisor can detect this event and update the forwarding filter on the host NIC accordingly.
QEMU patches addressing both issues have been posted on the QEMU mailing list.
An alternative could be to add a way for guest to request the switch between primary and standby through the PV device driver. This might reduce the downtime slightly: some PT drivers might enable bus mastering before they are fully ready to receive packets, causing a small window during which packets are still dropped.
This alternative approach is used by the netvsc driver. Using that with net_failover would require extending the Virtio interface and adding support to the net_failover driver in Linux, as of today no patches implementing this change have been posted.
As described above, some differences in behaviour between host NICs make failover implementation harder. While not yet widely supported, use of VF representors could make it easier to consistently configure host NICs for use by failover. However, for it to be helpful to userspace wide support across many NICs would be necessary.
Non-MAC based pairing
One basic question that had to be addressed early in the design was: how does failover master decide to which slave devices to bind? Unlike bond, failover by design can not rely on the administrator supplying the configuration.
So far, implementations focused on matching MAC addresses as a way to match slave devices. However, some configurations (sometimes called trusted VFs) do not supply VF MAC addresses by the hypervisor.
This seems to call for an alternative mechanism for locating the primary that is not based on the MAC address.
The netvsc driver uses a serial number value to locate the primary device. The serial is typically communicated through the VMBus interface and attached to a para-virtual PCI bus slot created for the device. QEMU/KVM traditionally do not have a para-virtual bus implementation, relying instead of emulating a PCI bus for VMs. One possible approach for QEMU would be to attach an ID value to a PCI slot, or bridge. For example, an ACPI Slot Unique Number, the PCI Physical Slot Number register, or an alternative vendor-specific ID register could be fit for this purpose. The ID could be supplied to the VM guest through the Virtio device. Failover driver would locate the slot based on the ID, and bind to any device located behind the slot. It would then program the MAC address from the standby device into the primary device.
An early implementation of this idea has been posted on the QEMU mailing list, however no patches to the failover driver have been posted yet.
Host network topology and other optimizations
In some configurations it might be better for the guest to use the PV interface in preference to the passthrough one. For example, if the PCI bus is very busy, and there’s spare CPU capacity on the host, it might be faster to send a packet that is destined to another VM on the same host through the hypervisor, bypassing the PCI bus.
This seems to call for keeping both interfaces active at all times. Supporting such an optimization would need to address the possibility of VM migration as well as the dynamic nature of the CPU/PCI bus available capacity, such that the specific interface used for sending packets to each destination can change at any time.
No patches for such support have been posted as of the time of writing of this article.
Specification status
Definition of the VIRTIO_NET_F_STANDBY has been included in the latest Virtio specification draft virtio-v1.1-csprd01.
Non-Linux/non-KVM support
Besides Linux, which systems could benefit from virtual network device failover support?
The DPDK set of userspace drivers is set to gain this support soon.
Drivers for other operating systems could also benefit from increased performance. One can expect the work on these drivers to start in earnest once the hypervisor support is widely available.
Other virtual devices besides Virtio could implement failover. netvsc already has a 2-device implementation that does not rely on the net_failover driver. It is possible that xen-netfront or vmxnet devices could use the failover driver. The author is not familiar with these devices.
Summary
A straight-forward sounding idea of improving performance for a Virtio network device by allowing networking traffic for the VM to temporary travel over a pass-through device exposed a wealth of issues on both VM host and guest sides.
Acknowledgements
The author thanks Jens Freimann for help analyzing netvsc as well as proof-reading the draft and suggesting corrections. The author thanks multiple contibutors who worked on implementation and helped review and guide the feature design over time.

No comments:
Post a Comment